通过卷积神经网络识别正方教务系统验证码
前言:
我们学校的的教务系统每次在可以查成绩的时候崩溃,需要刷个几百遍才能登录。正好最近练习爬虫,借助网上的cnn模板来破解学校的验证码,以后就可以自动查询啦。当别人还在苦恼登陆失败的时候,我早已得知挂科的真相流下了痛苦的泪水…ORZ。
什么是卷积神经网络?
我不打算讲有关卷积神经网络的具体推算方法以及数学上面的东西,因为网络上面已经有足够好的资源,我会在下面把自己学习的链接贴一下。我想说的是作为一个初学者,如何将这个东西拿来用。“使用”与“精通”之间有很大区别。
如何理解神经网络
借用吴军老师的话:
神经网络与人脑没有半点关系,它的本质是有向图。
不过它与一般的有向图有点区别
1、在人工神经网络中,所有的节点都是分层的,每层节可以通过有向弧指向上一层节点,
但是同级之间没有弧连接,而且不能越过上层直接连接到上上层。
2、每一条弧有一个值(称为权重和权值),根据这些值,可以计算出他们的下一个层的值。
人工神经网络就是上述的数学模型,它擅长的是模型分类。
在人工神经网络中,需要设计的部分只有俩个,一个是它的结构,即网络分成几层、每层
几个节点、节点之间如何连接:第二就是他们的计算函数的设计。
那么如何得到好的权值呢,这就要涉及到对人工神经网络的训练了。
训练神经网络主要依靠数据来对参数用梯度下降的方法找最优解。
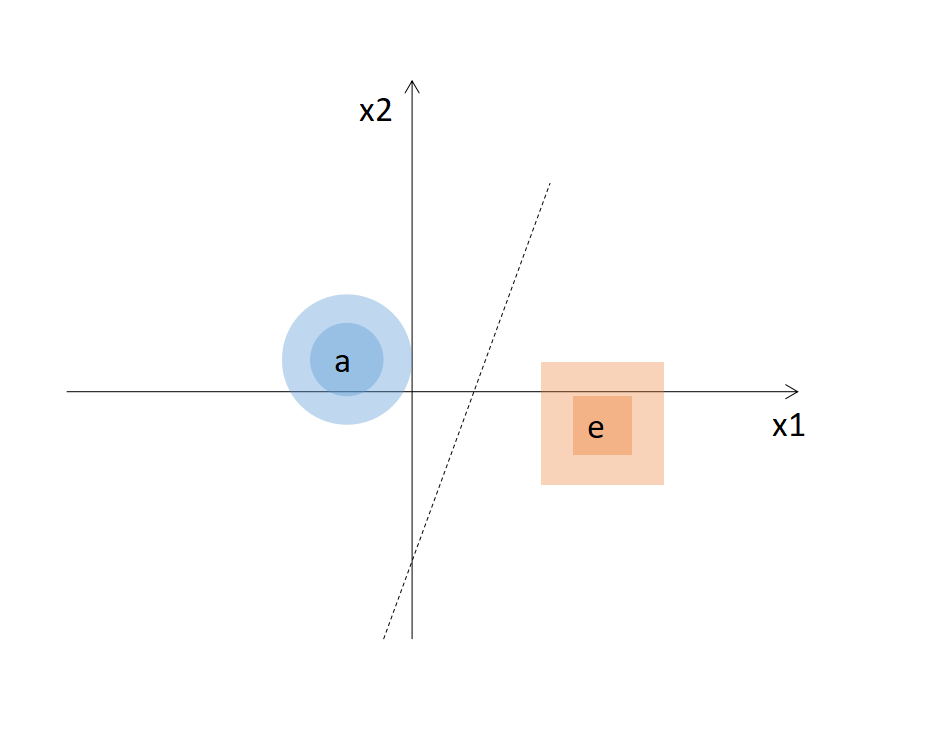
假设在一个二维空间中,我们需要区分a与e区域,它们的分布如上图所示。我们这个模型的任务就是要在空间里切一刀,将a和e分开。上图中的虚线便是分割线,左边是a,右边是e,如果新的元素进来了,落到左边我们就将它判断成a,反之则被认为是e。现在可以用一个人工神经网络来实现这个简单的分类器(虚线),该网络的结构如下:
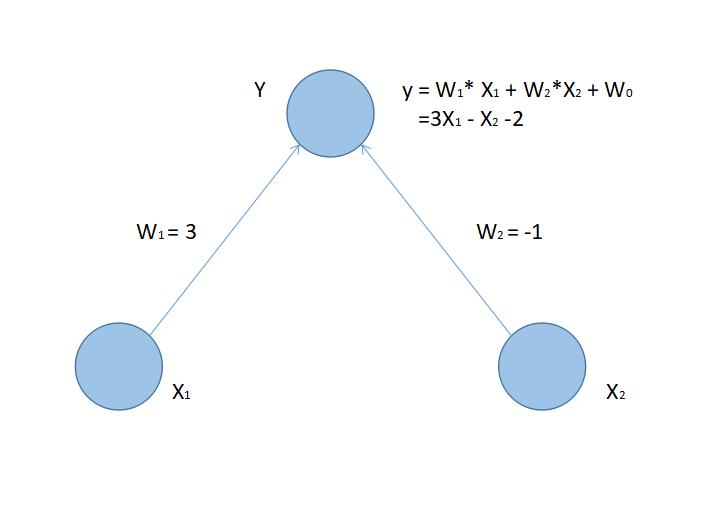
这是一个再简单不过的人工神经网络了。在这个人工神经网络中,有两个输入节点:X₁和X₂,一个输出节点Y。在X₁到Y的弧上,我们赋予一个权重W₁ = 3,在从X₂到Y的弧上,我们赋予权重W₂ = -1,然后将Y这一点上的数值设定为两个输入节点数值X₁和X₂的一种线性组合,即y = 3X₁ - X₂。注意上面的函数是一个线性函数,他也可以被看成是输入向量(X₁,X₂)和(指向Y的)各条有向弧的权重向量(W₁,W₂)的内积(也叫做点积)。为了后面判断时方便起见、不妨在公式中再加一个常数项-2,即
y = 3X₁ - X₂ - 2
现在将平面上面的一些点(0.5,1)、(2,2)、(1,-1)和(-1,-1)的坐标输入到第一层的两个节点上,然后看看在输出节点得到了什么值。
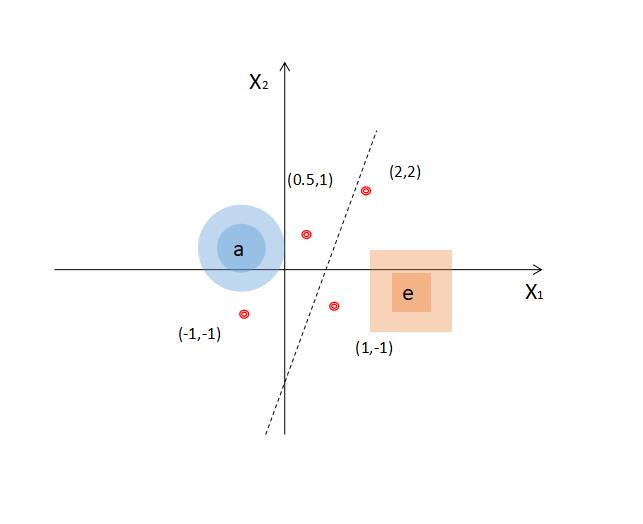
(0.5,1) >> -1.5
(2,2) >> 2
(1,-1) >> 2
(-1,-1) >> -4
于是就可以说,如果在输出的节点Y得到的值大于零,那么这个点就属于e类,反之则属于a类。我们用神经网络定义了一个线性分类器,它可以做到简单的任务。
上述例子摘自吴军老师的《数学之美》
CNN
关于cnn,它属于神经网络的一种,所以拥有上述神经网络的特性,它是特殊的有向图,它是一个关于图像的分类器。关于cnn的工作原理我推荐一篇文章,其中很详细的阐述了cnn的原理。
如何实现
原理就说到这儿了,那么用什么工具实现呢?我使用的是谷歌的开源人工智能系
TensorFlow。前面说过了人工神经网络其实就是有向图,那么TensorFlow其实就是搭建有向图的工具,具体的使用方法请查看官方文档,英文学渣(就是本人)可以看TensorFlow中文文档
训练代码CNN部分
处理文件的方法用的是斗大的熊猫博客例子,CNN框架以及参数来自知乎一篇专栏。
1 | def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1): |
关于训练量,总共从官网爬了1500张下来,人眼识别了一下午(吐血)。成功率大概50%,我在登陆程序上让它自己迭代,失败就继续尝试访问,问题不大。
下面贴一下神经网络的相关学习链接
莫烦的人工神经网络教程Hellobi Live的人工神经网络的教程
colah’s blog
## 登陆教务系统
模型训练完了,下一步就是实现自动登陆了。
难点
1.方正教务系统在提交表单的时候除了必要的学号密码等等,还需要提交一个VIEWSTATE值。解决方法就是先get一次,获取到VIEWSTATE值,再post。
2.方正教务系统在早上的url中会带有一串乱码字母,每次get网站这串字母都会变。需要保持验证码的地址和get的地址都带有一样的乱码,这样验证码才能与地址吻合。
3.登录成功后将会对登录界面进行一次get,用来获取成绩界面的__VIEWSTATE值,这次get必须带有表头,表头中的Referer要带有学号。这很关键。
登录代码
1 | import os |
关于验证码的处理模块,我自己用PIL对验证码进行了一个预处理,将图像二值化并且去掉了噪点,我会在最下面将自己的代码分享
贴一下成功后的截图~~
可以看到失败一次后继续访问,然后就登录成功了
最后
在对神经网络的学习过程中,感到数学的力量真的是强大的。数学家们用非常简洁的数学模型确能形成如此复杂的系统,从而揭示规律。然而数学也是艰涩的,我在查看文档资料的时候充分认识到自己数学的薄弱。但是如果一头扎进数学的海洋,我可能就不能在短时间内解决教务系统自动登陆的问题了。在今后的实践中肯定也有这种问题出现,知识具有层级结构,在深入多少层后停止,将剩余看做黑箱是需要思考的。目前我想遵循的原则是AK47原则,简单、杀伤大:也就是说用最简单的方法达到目的。
这是这个项目的仓库,可以在这里找到所有代码